

Designing for Life Science – from 0 to 1
Learnings from the design process

Designing for life science can be particularly tricky because scientists often deal with vast amounts of unstructured data and need tools that can handle complex workflows. As the founding frontend engineer and UX designer, I designed and implemented a frontend that meets these unique needs. This blog post will walk you through the design process and key findings along the path from 0 to 1.
Understanding the problem
The first step in the design process is to clearly understand the problem. Scientific research generates vast amounts of unstructured data. Computational biologists and bioinformaticians create pipelines to process these types of data, and scientists run these pipelines to analyze their research. Bench scientists and computational biologists may be on the same team or on different teams.
User research
At Mantle, our user research involved shadowing scientists working in the lab, allowing us to understand their workflows and challenges firsthand. By asking scientists to walk us through their processes, we gained valuable insights. Our team’s strong science background played a crucial role in these visits by facilitating in-depth discussions.
A key finding was that scientists generate data of different types (using different instruments or assays) for different samples, and they prefer to group data by sample or sample property. For example, instead of categorizing by data type (e.g. all flow cytometry data), they organized datasets related to a specific sample, which could involve multiple data types (e.g. sample 123’s flow cytometry, sequencing, and ELISA data).This insight helped us design a data management system that aligns with their natural organizational habits, making their workflows more intuitive and efficient.
Define the problem and ideate
After brainstorming with the team, we identified critical "how might we" questions that guided our design process:
How might we make searching and filtering for datasets fast and intuitive?
How might we make pipeline versioning and releases easy?
How might we better communicate the science and progress to biotech leaders?

These questions helped us define the core problems: scientists struggle with unstructured data and need an intuitive way to search and filter datasets. They also require an easy method for pipeline versioning and releases. Their leaders need clearer communication of scientific progress. Addressing these issues became our primary goal as we began ideating solutions to enhance data management, streamline workflows, and improve overall efficiency in the lab.

Design and prototype
Working at a fast-paced startup like Mantle, our approach is to learn rapidly by releasing products and gathering feedback directly from our users. We don't have the luxury of conducting in-depth user studies, creating detailed user journeys or spending a lot of time on medium fidelity prototypes. Thus, we prioritize solutions that meet the minimum viable requirements, are easy and quick to build, and can be launched as fast as possible.
Instead, here are some solutions we focused on that target each of our personas.


Once we settled on promising ideas, I created high-fidelity prototypes on Figma.
Data management

Goals:
Easily search and filter by creator, usage, and modification date.
Save frequently used filters for quick access.
Identify and organize datasets by type (e.g., Flow, Sequencing, Image).
View IDs, names, creators, and last modified dates.
Show additional dataset properties for more detailed information.
Quickly upload new datasets.
Star important datasets or archive inactive ones.
Pipeline versioning

Goals:
Easily switch between different pipeline versions from a dropdown menu.
View and manage all pipeline runs, including details such as run ID, name, date, status, creator, and updater.
Quickly see the status of each run (e.g., running, completed, queued, error).
Access detailed information about the current pipeline version, including repository name, GitHub URL, config info, and description.
Import templates and create new runs with the click of a button.
Dashboard
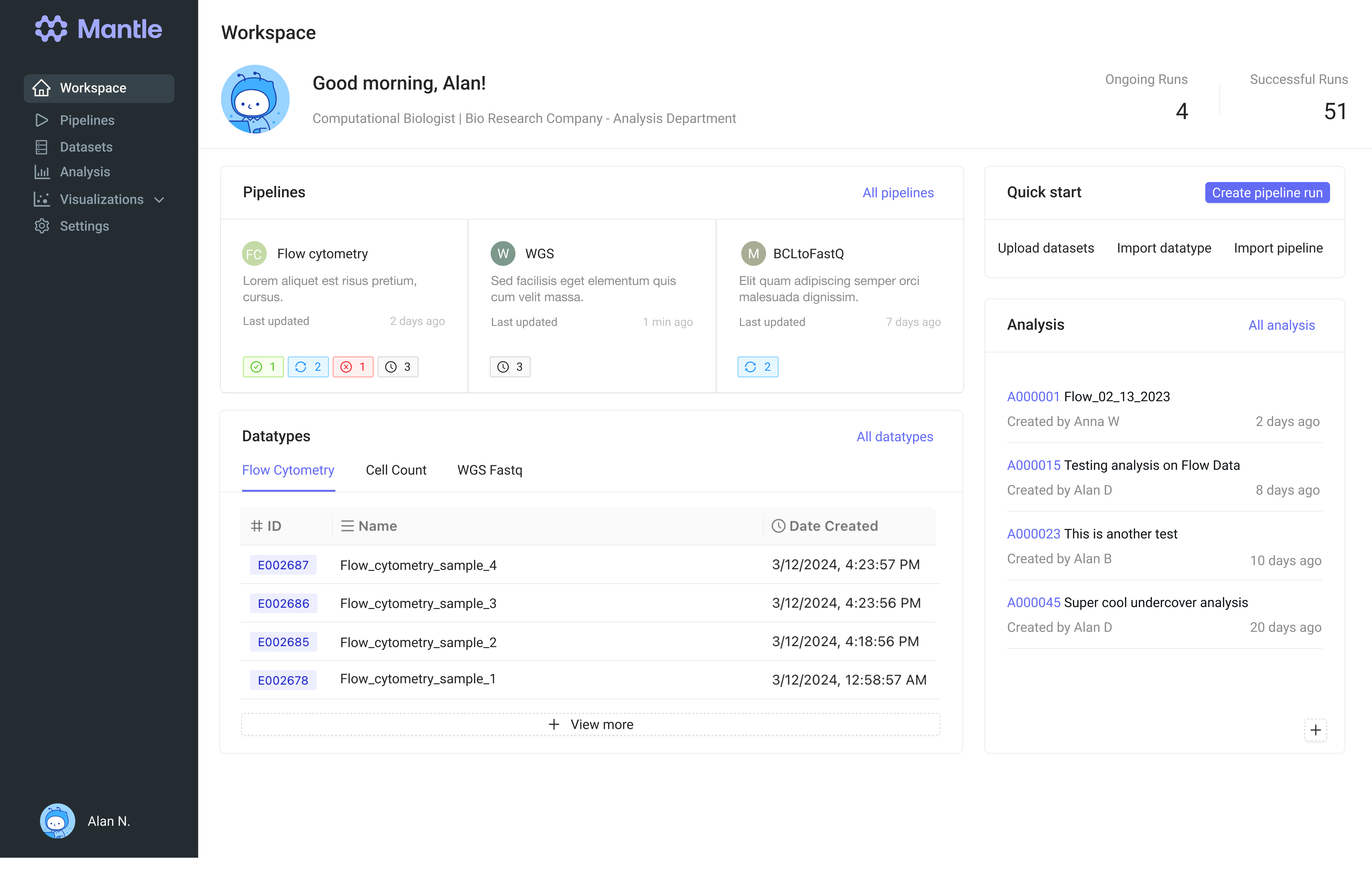
Goals:
Displays key pipelines with their last update, status indicators, and quick access to all pipelines.
Lists data types with a tabbed interface for quick navigation, showing recent dataset entries and creation dates.
Easy access to create a pipeline run, upload datasets, import data types, and import pipelines.
Lists recent analyses with creation dates and quick links to detailed views.
Overview of ongoing and successful runs, providing a snapshot of current activity.
Implementation
As both a designer and a coder, I am aware of the challenges that arise during the implementation phase and keep them in mind when designing. At Mantle, we leverage Ant Design for our UI components. Although Ant Design has some design limitations, it allows us to implement features rapidly, which is crucial in our fast-paced environment.
To further enhance our workflow, I utilize ChatGPT for problem-solving and ideation. For those interested in improving their prompt engineering skills, consider exploring dedicated courses.
My approach involves setting the context for ChatGPT as an expert in the relevant field and then posing specific questions related to that expertise. This method has been instrumental in quickly overcoming complex challenges and accelerating our development process.
Continuous improvement
The design journey never truly ends. We plan to conduct further usability tests, iterate on our designs, and uncover new user insights. Continuous improvement will help us stay aligned with the evolving needs of scientists and computational biologists, ultimately driving more impactful scientific discoveries. Our journey is just beginning, and we are excited to continue refining and expanding our platform to support the future of biotech.
If you’d like to try Mantle, sign up for a free account here.
 | A guest post by
|